
OpenAI API 初体验
一、写在前面
对于非程序员来说,你问他什么是 ChatGPT,他可能会回答你,不就一AI聊天 嘛!
要这么回答也没错,实际上 ChatGPT 背后的公司叫 OpenAI,ChatGPT 只是他们实现的其中一个应用,ChatGPT 目前 GPT-3.5 是免费使用的,甚至后面还会开放 GPT-4o免费使用。
实际上他们也提供相关的接口,这里叫 OpenAI API。这也就意味着,依托于 OpenAI API,个人开发者也可以开发属于自己的AI应用,而不需要自行进行大模型开发。这就好比手机应用开发,而不需要进行手机系统开发。
二、如何使用
1、开发环境:
我的开发环境如下:
- MacOS
- Python
参考官方文档开发者快速入门,这里记录下我的操作步骤,详情请见官方文档。
2、创建 API 秘钥
在 OpenAI平台 上创建一个项目秘钥。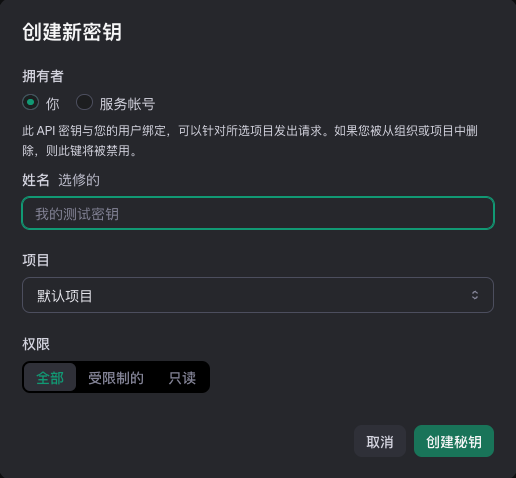
创建后注意复制保存好,因为安全原因,无法再次查看。假设这里得到的秘钥是:sk-proj-aaabbbcccddd233666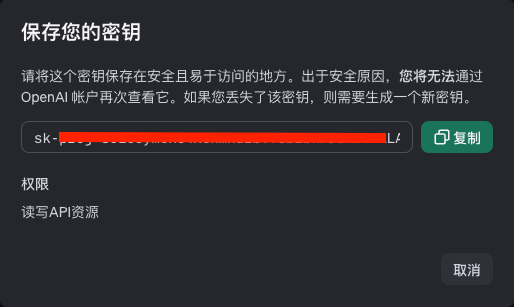
3、Python 环境
我使用的是 pyenv 来管理本地多版本 Python,因为 OpenAI API 要求 至少需要 Python 3.7.1 或更高版本,我切换到 Python 3.8.13
4、创建项目文件夹
创建项目文件夹 openai-api-demo ,并进入该文件夹中。
1 | mkdir openai-api-demo |
5、虚拟环境
安装虚拟环境
1 | python -m venv openai-env |
激活虚拟环境
1 | source openai-env/bin/activate |
如果激活成功,会看到终端最新行开头为 (openai-env)
6、安装 openai
在虚拟环境中安装 openai
1 | pip install --upgrade openai |
查看是否安装成功
1 | pip list |

7、设置 API 密钥
官方文档分 为所有项目设置API密钥 和 为单个项目设置API密钥。
这里我选择后者。在 openai-api-demo 文件夹下,新建 .env 文件并打开。
将你的秘钥写入该文件,格式如下:
1 | OPENAI_API_KEY=sk-proj-aaabbbcccddd233666 |
8、.gitignore
上面的秘钥不能公开暴露,如果需要将项目托管到公开的仓库,需要在 openai-api-demo 文件夹下新建 .gitignore,然后添加一行: .env。
9、安装python-dotenv
将秘钥配置到项目的 .env 下,需要通过 python-dotenv 来加载。不清楚为什么 OpenAI API 文档没有提及。
1 | pip install python-dotenv |

10、第一个API请求
以上配置了 Python 和 OpenAI API 秘钥,接下来就可以使用 Python 库向 OpenAI API 发送请求了。在 openai-api-demo 文件夹下创建 openai-test.py 文件,复制并粘贴以下内容。工程地址
1 | from dotenv import load_dotenv |
执行命令,以运行代码:
1 | python openai-test.py |
不出意外的话,你可能会遇到这个问题:raise APITimeoutError(request=request) from err openai.APITimeoutError: Request timed out.
这是因为被墙了,需要一点点科学上网。。[捂脸][捂脸][捂脸]
接下来就是这个问题:Error code: 429 - {'error': {'message': 'You exceeded your current quota, please check your plan and billing details. For more information on this error, read the docs: https://platform.openai.com/docs/guides/error-codes/api-errors.', 'type': 'insufficient_quota', 'param': None, 'code': 'insufficient_quota'}}
通过查阅 Error codes,原来是超过配额。也就是说 OpenAI API 是收费的,由于我还没有进行任何付费,因此会报这个错误。
三、关键概念
理解一些关键概念,有助于我们更好的使用 OpenAI API 。也可以更好的理解 GPT 的整个的运作原理。
1、文本生成模型 Text generation models
文本生成模型通常称为 generative pre-trained transformers(生成预训练Transformer),即 GPT。其中 GPT-4 和 GPT-3.5 是两个具体的模型版本。这些模型被设计和训练来理解自然语言和形式语言。
- 自然语言:人类日常交流使用的语言
- 形式语言:计算机编程语言等有严格语法规则的语言
GPT 模型能够根据输入的文本(称为“提示”)生成相应的文本输出,这意味着模型可以根据给定的提示生成回答、文章、代码等。设计提示是使用 GPT 模型的关键步骤。提示可以看作是一种“编程”方式,通过提供具体的说明或示例来指导模型如何完成任务。
GPT 模型可以应用于多种任务,包括但不限于:
- 内容生成:自动生成文章、故事或其他文本内容;
- 代码生成:生成或补全代码片段;
- 摘要:将长篇文章或文档缩减为简短的摘要;
- 对话:与用户进行自然语言对话,模拟人类交流;
- 创意写作:辅助或自动生成具有创造性的文本内容。
2、助理 Assistants
助理指实体,在 OpenAI API 的背景下,通常是由大型语言模型(如GPT-4)提供支持的,目的是帮助用户执行各种任务。助理的操作基于模型上下文窗口中嵌入的指令,上下文窗口可以理解为模型处理和理解输入文本的一段文本区域,决定了助理能够“记住”和参考的信息范围。助理不仅可以执行简单的任务,还可以使用特定的工具来执行跟复杂的任务,例如:
- 运行代码:执行编程代码,这在需要逻辑或数据分析的任务重非常有用;
- 从文件检索信息:能够从用户提供的文件中提取和检索信息,这在处理文档、数据表和网页内容时很有帮助。
具体请参考助理 API 概述
3、嵌入 Embeddings
是一种将文本、单词或短语转换成高维向量空间的技术。这些向量可以捕捉到单词或短语之间的语义关系,使得相似的单词或短语在空间向量中彼此接近。几个关键点:
- 语义理解:嵌入向量能够捕捉单词的语义信息,使得具有相似含义的单词在向量空间中距离近;
- 降维:尽管原始文本数据是高维的,但嵌入可以将这些数据降维到一个更小的维度空间,同时保留重要的语义信息;
- 应用广泛:嵌入可以用于各种自然语言处理(
NLP)任务,如文本分类、情感分析、机器翻译和信息检索等; - 预训练模型:
OpenAI使用预训练模型来生成嵌入向量,这些模型在大量文本数据上进行了训练,以学习语言的复杂模式; - 计算效率:嵌入向量可以快速计算,并且用于高效的相似性搜索和聚类;
- 兼容性:生成的嵌入向量可以很容易地与其他机器学习模型结合使用,以提高性能;
- 细粒度:嵌入不仅能够捕捉单词之间的关系,还能够捕捉单词在不同上下文中的细微差别;
- API访问:通过
OpenAI API,开发者可以轻松将嵌入技术集成到自己的应用程序中,而无需从头开始实现复杂的NLP算法。
4、代币 Tokens
在 OpenAI API 中,Tokens 是指文本的基本单位,它们是理解和处理文本的最小片段。对于自然语言处理(NLP)任务至关重要,因为它们允许模型将输入文本转换为计算机可以处理的格式。以下是一些关键点:
- 文本分割:Tokens 是将文本分割成模型可以理解的小块的方式。每个 Token 可以是一个单词、一个短语或者是单个字符,这取决于所使用的分词方法;
- 编码:Tokens 通过编码转换为数字,这样模型就可以使用它们进行计算。这些编码通常是连续的向量,可以捕捉单词或短语的语义信息;
- 上下文感知:在一些先进的模型中,Tokens 不仅代表单个单词,还可以包含有关其在句子中位置的信息,这有助于模型更好地理解语言的上下文;
- 模型限制:不同的模型可能对 Tokens 的数量有限制。例如,一些模型可能只能处理一定数量的 Tokens,这限制了可以处理的文本长度;
- 优化:在某些情况下,为了适应模型的限制,可能需要对文本进行优化,比如通过缩短句子或使用缩写来减少 Tokens 的数量;
- 分词器:OpenAI API 和其他 NLP 工具通常包括分词器(Tokenizer),它们负责将文本转换为 Tokens。分词器可以是简单的,也可以是复杂的,能够处理各种语言特性;
- 效率和性能:正确地处理 Tokens 对于模型的性能至关重要。无效的 Tokens 处理可能导致模型无法正确理解输入的文本,从而影响输出的准确性;
- API集成:通过 OpenAI API,开发者可以利用预训练模型的分词功能,将用户的文本输入转换为Tokens,然后进行各种NLP任务,如文本生成、翻译或摘要;
- 多语言支持:高质量的分词器能够处理多种语言,为不同语言的文本提供准确的Tokens;
- 自定义:在某些情况下,开发者可能需要自定义分词器来处理特定的语言或领域特定的术语。
 微信
微信 支付宝
支付宝




